
The Ballot Counting Room
Why how we count votes is a completely separate question from how we cast them — and why getting it wrong poisons the whole conversation

You probably haven’t given much thought to the counting room, at least not to the counting part.
When you vote, you fill out a ballot. Somewhere, at some point, people count those ballots and announce a winner. The part you can see — your ballot, your choice, the candidates on your screen — gets all the attention. The counting part happens out of sight, run by election officials with specialized software, and most people assume it’s just... arithmetic.
It is arithmetic. But it’s arithmetic with choices baked into it. And those choices determine what your vote actually means — what information gets used, what gets thrown away, and who ends up winning.
This article is about that hidden decision. We’ve spent the previous articles in this series talking about expressive voting — systems that let you say more than just one name on your ballot. But there’s a question that comes before any vote is cast: once voters have expressed their preferences, how do you count them?
The answer matters more than most people realize. And a lot of the heated debates about ranked-choice voting, approval voting, and election reform in general have been arguing about the wrong thing — confusing the question of what you say on your ballot with the question of how those words get counted.
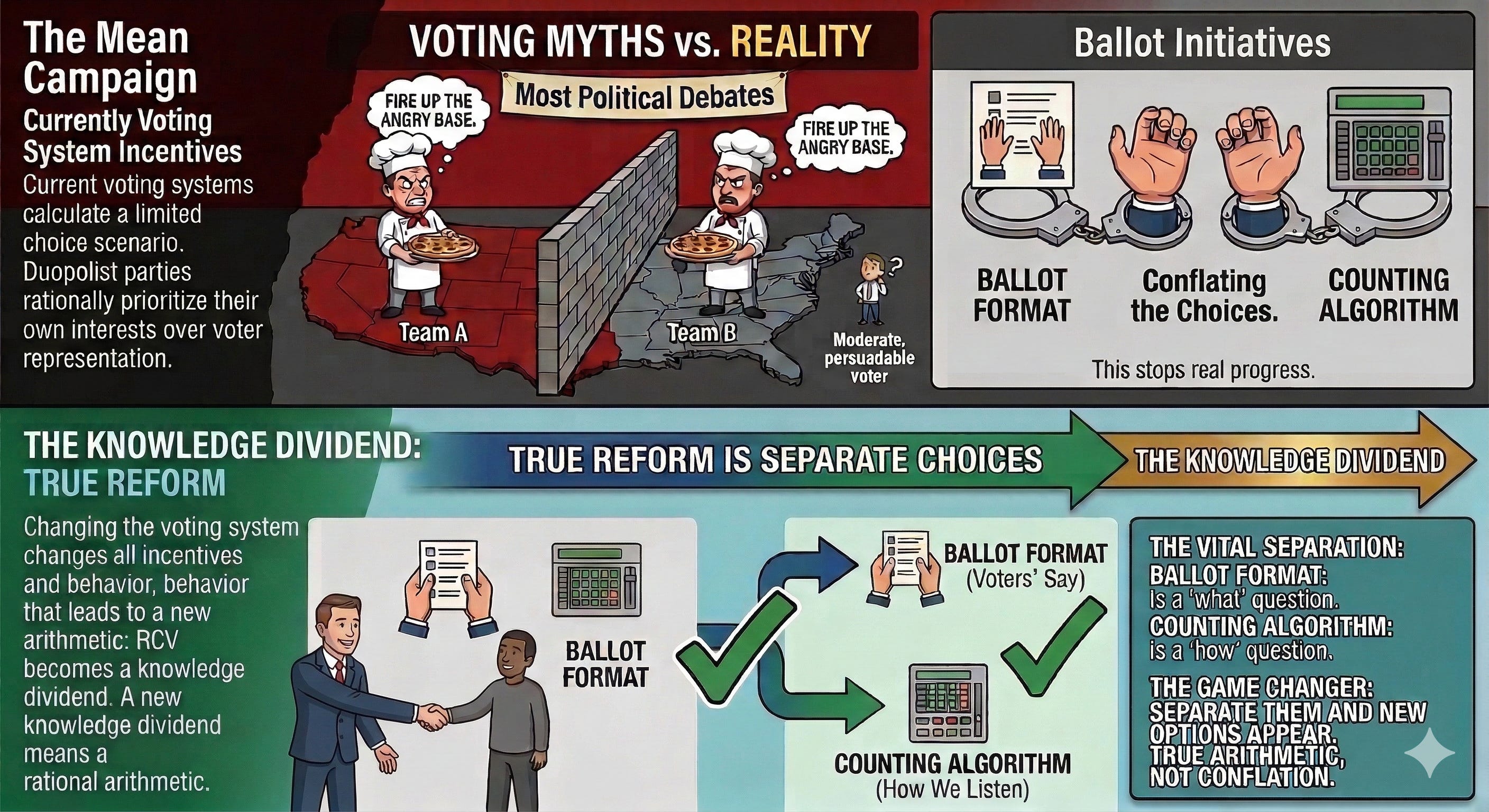
1. Two Completely Different Questions
Imagine you’re running a restaurant survey. You ask your customers: “Please rank your top three dishes from 1 to 3.” Simple enough. But now you have to actually use those rankings to decide which dish to feature next month.
Do you pick the dish that got the most first-place rankings? The one with the highest average rank? The one that nobody ranked last? The one that the most people ranked in their top three? These all seem reasonable, and they can produce completely different winners from the exact same pile of survey cards.
That’s the counting problem. The ballot is one thing. The algorithm — the mathematical procedure you use to turn ballots into a winner — is a separate thing entirely. You can change the algorithm without changing a single ballot. You can use the same algorithm on radically different ballots. The two decisions are independent.
In current American election debates, these two questions are almost always run together as if they were one question — perhaps intentionally so. When someone says “I oppose ranked-choice voting,” they might mean they don’t want voters to rank candidates. Or they might mean they don’t like the specific counting algorithm — called instant runoff voting — that is almost always used to tally ranked ballots. These are different objections that call for different responses. But they almost never get separated.
The ballot is what voters say. The algorithm is how we listen. Confusing these two things has derailed the entire reform conversation.
This article is going to separate them clearly, explain what the different counting algorithm families actually do, and then make what should be a straightforward argument: most of the serious objections to electoral reform are objections to specific counting algorithms — not to the idea of expressive voting itself. Fixing the algorithm is often much easier than the opposition to expressive voting wants voters to believe.
2. What a Counting Algorithm Actually Does
A counting algorithm is a set of rules that takes a pile of ballots as input and produces a winner as output. That’s it. The rules can be simple — “count the marks, highest number wins” — or they can be complicated. But they are always a choice, and that choice always involves tradeoffs.
Think back to the signal and noise framing from the first article in this series. Your ballot is a message. It contains information about what you want. The counting algorithm is the decoder — it takes all those messages and tries to extract the meaning. A badly designed decoder throws away most of the signal. A well-designed one uses as much as it can.
Every counting algorithm in use today makes a different decision about what to preserve and what to discard. To understand the debate, you need to understand that decision for each of the main families.
3. The Main Counting Families
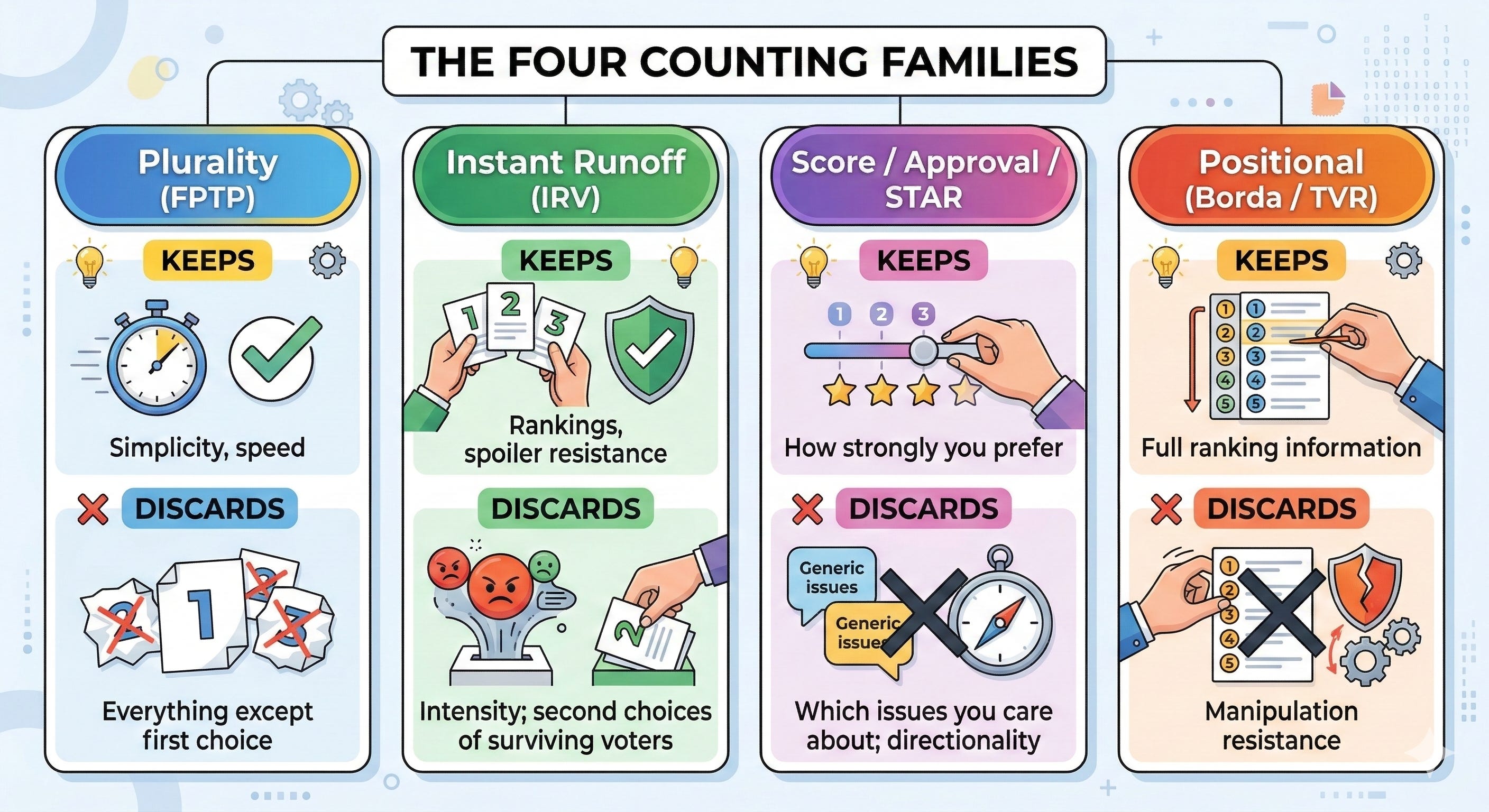
Family One: Mark the Highest Number (Plurality)
This is First-Past-the-Post. Mark one candidate. Count the marks. Whoever has the most marks wins — even if that’s less than half the voters.
What it preserves: simplicity and speed. Counting is fast, transparent, and anyone can verify it.
What it discards: almost everything else. It knows your first choice but nothing about your second, third, or how strongly you preferred your first choice to your second. A voter who passionately supports candidate A and would accept candidate B is coded identically to a voter who passionately supports candidate A and would rather the city burn than see candidate B win.
The compounding problem: when more than two candidates run, the winning threshold drops below 50%. The 1992 presidential election produced a three-way split that let Bill Clinton win with 43% of the vote. The 2000 Florida recount came down to 537 votes, with Ralph Nader receiving 97,421 — votes that could have gone elsewhere if voters hadn’t faced the all-or-nothing choice the algorithm imposed.
Family Two: Eliminate the Last-Place Finisher (Instant Runoff)
This is the algorithm that gets referenced to by many names: ranked-choice voting, instant runoff voting, or IRV. Voters rank candidates in order. If no candidate has a majority of first-choice votes, the candidate with the fewest is eliminated and their voters’ second choices are redistributed. Repeat until someone has a majority.
What it preserves: ranking information, spoiler-resistance, and majority winners. Voters can honestly rank their true first preference without worrying that doing so will help their least favorite candidate win. The winner has support from at least half the still-active ballots.
What it discards: intensity of preference, and second-choice information for voters whose candidates didn’t get eliminated. This is the critical point that almost never gets explained clearly. Under IRV, if your candidate survives to the final round, your second-choice vote is never consulted. A voter who barely preferred A to B, and would gladly accept C, gets counted the same as a voter who despises B and C equally.
There is also a specific, documented undesirable mode. In the August 2022 Alaska special election for Congress, a candidate named Nick Begich was eliminated in the first round — but the full ballot data revealed that Begich would have beaten both other candidates in any direct head-to-head matchup. He was the candidate most broadly acceptable to the most voters, and the counting algorithm eliminated him before that broader preference could register. This type of failure — eliminating the most broadly acceptable candidate early because their first-choice support is split — has a name in voting theory: the center squeeze.
The Alaska 2022 Example — Same Ballots, Different Algorithms
Three candidates: Mary Peltola (D), Sarah Palin (R), Nick Begich (R). First-choice vote shares: Peltola 40%, Palin 31%, Begich 29%.
Under standard IRV: Begich eliminated (fewest first-choice votes). Palin voters’ second choices redistributed. Peltola wins 51-49.
Under head-to-head comparison: Begich beats Peltola. Begich beats Palin. Begich is preferred over both other candidates by the majority of Alaska voters — and is the only candidate no majority actively opposes.
Same ballots. Different algorithm. Different winner. This is not necessarily a flaw in the voters’ expressions — it is a flaw in the counting procedure that fails to use the information those voters provided.
Family Three: Score Every Candidate (Approval and STAR)
Approval voting asks a simple question: for each candidate, do you find them acceptable? Mark as many as you like. Most approvals wins. No rankings, no second chances — just a yes or no for each candidate.
STAR voting (Score Then Automatic Runoff) goes further. Score each candidate from 0 to 5. The two highest-scoring candidates advance to an automatic runoff, where the candidate preferred by more voters wins.
What these preserve: intensity information. A voter who scores candidate A at 5 and candidate B at 1 is telling you something that a ranked ballot can’t capture — not just that they prefer A, but how strongly. In a close race, this distinction can be decisive.
What they discard: directional preference structure. Whether a voter cares deeply about the environment and moderately about healthcare, or the reverse, the algorithm sees the same scores if the candidates happen to receive the same numbers. Two voters with mirrored priorities but identical scores produce identical outputs.
There is also a legal complication for STAR in many states. State constitutions often require elections to produce a winner by “plurality” or “majority” of votes. STAR’s two-stage process — scoring, then runoff — has been challenged in court on the grounds that it doesn’t clearly satisfy either standard. Legal clearance is required on a state-by-state basis before STAR can be implemented.
Family Four: Total the Positions (Borda and Positional Systems)
The Borda count assigns points based on rank position. In a three-candidate race, first place is worth 2 points, second place is worth 1, third place is worth 0. Sum the points across all voters. Highest total wins.
The Total Vote Runoff proposed by economist Eric Maskin is a variant: instead of eliminating the candidate with the fewest first-choice votes (as in IRV), eliminate the candidate with the fewest total positional points. This guarantees that if a Condorcet winner exists — a candidate who beats everyone else head-to-head — they won’t be eliminated early. It would have elected Begich in Alaska 2022.
What these preserve: information from every voter’s entire ranking, not just their top choice. The Borda/positional family is the first family that can rescue a broadly acceptable middle candidate from the center-squeeze problem.
What they discard: manipulation resistance. Borda count is famously vulnerable to a tactic called “clone nomination” — a party that runs two similar candidates can split their opponents’ points across both, gaining a structural advantage. More broadly, these systems reward strategic ballot-stuffing in ways that are harder to prevent than in other families.
4. The Objections — and Which Ones Are Real
Now that we’ve separated the ballot question from the counting question, we can evaluate the standard objections to electoral reform much more precisely. Most of them turn out to be objections to a specific algorithm — not to expressive voting as a concept.
Objection Decoder
“RCV is too complicated for voters.”
This is an objection to the ballot format — asking voters to rank candidates — not to any counting algorithm. Research consistently shows that voters find ranking intuitive. In Santa Fe’s first RCV election, 84% of voters said the ballot was not confusing. The complexity objection is also selectively applied: FPTP requires voters to perform invisible strategic calculations (”is my candidate viable?”) that are far more cognitively demanding than simply saying “I prefer A to B to C.”
“It can eliminate the candidate most voters preferred.”
This is a legitimate objection — but it is an objection to the IRV counting algorithm specifically, not to ranked ballots. The Borda/positional family fixes this problem while using the same ballot. The objection is solvable by changing the algorithm, not by abandoning expressive voting.
“Results take too long.”
If you ignore that this is being compared to a runoff election, this is a real operational concern for some IRV implementations, but it is an administration and software problem, not a fundamental property of expressive voting. Most jurisdictions using RCV now report preliminary results within 24 hours. Approval voting and STAR produce results as quickly as FPTP.
“My vote could end up counting for someone I didn’t vote for.”
Under IRV, if your first-choice candidate is eliminated, your ballot transfers to your second choice. This is not your vote being hijacked — it is your vote being used exactly as you instructed by ranking a backup preference. Under FPTP, if your first-choice candidate loses, your vote counts for no one at all. Compared to that, a transferred vote is a feature.
“The algorithm can be gamed.”
Every algorithm can be gamed. FPTP is gamed every election — it’s called strategic voting, and it forces millions of voters to abandon their true preferences for “viable” candidates. IRV is harder to game than FPTP. More sophisticated counting methods raise the cost of manipulation further. The question is not whether gaming is possible but how hard it is to do, and whether it’s harder or easier than the system being replaced.
5. The Question Nobody Is Asking
There is a deeper point lurking behind all of these comparisons, and it’s one the reform debate has almost entirely avoided: we are living through the most significant expansion of information-processing capacity in human history, and our counting algorithms were designed for pencil-and-paper tabulation in the nineteenth century.
FPTP was efficient when counting meant physically moving slips of paper into piles. IRV was a meaningful improvement when computers first made sequential elimination calculations feasible. But we now live in a world where every smartphone contains more raw computing power than the largest supercomputers of the 1980s, where machine learning routinely extracts latent structure from enormous, messy datasets, and where the mathematical tools to process rich, multi-dimensional preference information have advanced beyond anything the founding generation of social choice theorists could have imagined.
The political science literature has understood for decades that voter preferences are genuinely multi-dimensional — that voters don’t just prefer one candidate to another on a single left-right axis, but hold distinct views across different policy areas that interact in complex ways. The spatial voting theory pioneered by researchers in the 1950s and refined ever since makes this explicit: voters are points in a multi-dimensional issue space, and candidates are also points in that space, and what a voter really wants is the candidate whose position is closest to theirs across all the dimensions they care about.
Our ballots communicate in a language our counting algorithms cannot read. We ask voters to express multi-dimensional preferences and then throw away most of what they said.
Current counting algorithms respond to this complexity by ignoring it. FPTP keeps one bit. IRV keeps a ranking that discards intensity. STAR keeps intensity but loses directionality. None of them operate in the multi-dimensional space where the preferences actually live.
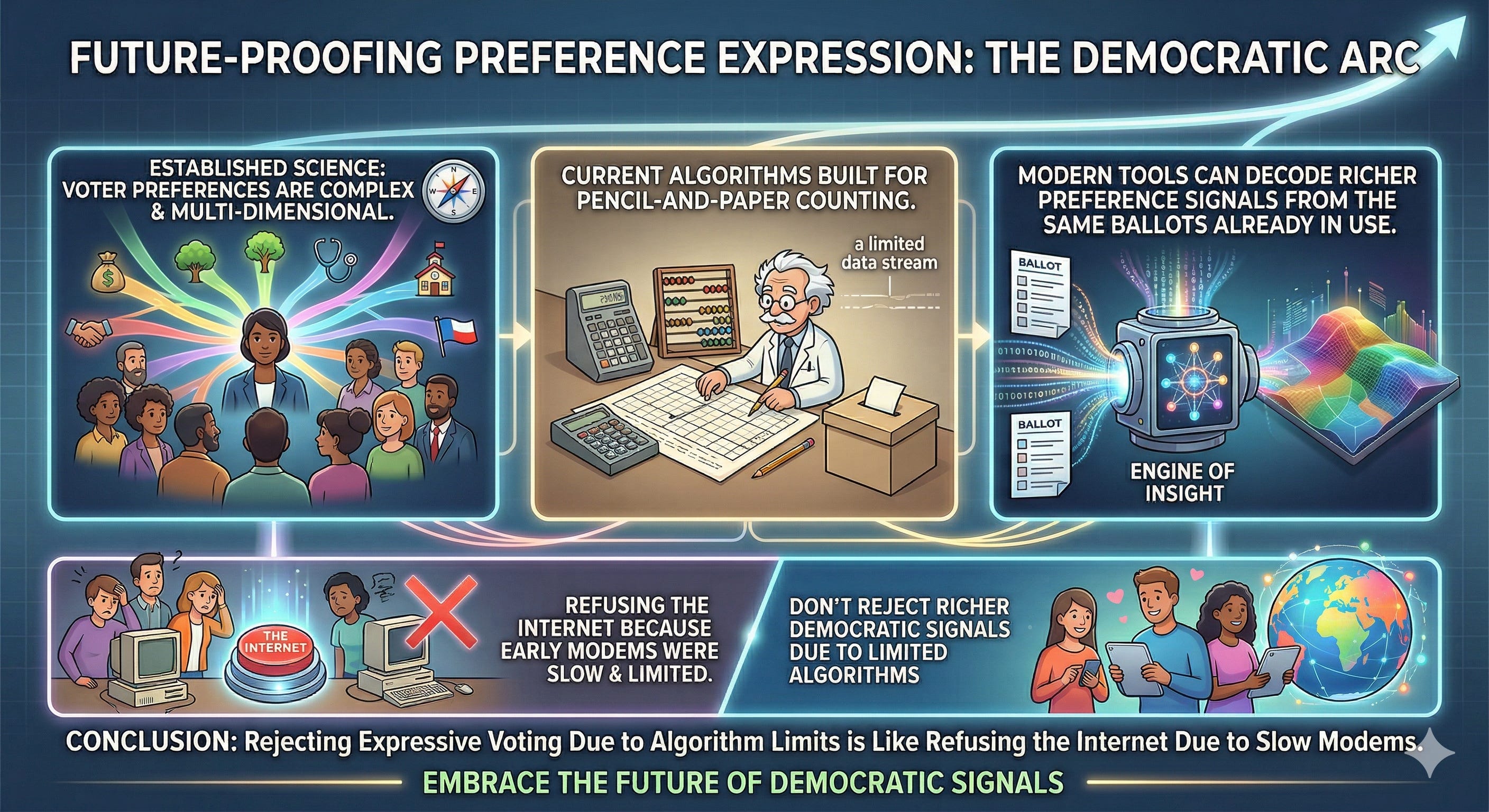
The frontier of social choice research — drawing on tools from information theory, machine learning, privacy-preserving data aggregation, and mathematical economics — is beginning to ask whether this gap can be closed. The theoretical groundwork for counting methods that could process genuinely multi-dimensional preference information already exists. Such methods could, in principle, operate on the same ballots already in use, require no new voter education, transmit compact and verifiable summaries rather than full ballot records, and still extract substantially more of the preference signal that voters are already providing.
None of these methods are yet in use. The formal theory is young and requires substantial further development before any real election could adopt them. But the direction is clear, and it matters for how we think about the debate happening right now.
The objections to today’s counting algorithms — the center-squeeze problem in IRV, the intensity-loss in rankings, the directional-blindness of scoring — are not permanent features of expressive voting. They are limitations of specific algorithms that were designed under constraints that no longer apply. Rejecting expressive voting because of those limitations is like refusing to use the internet because early modems were slow.
6. The Policy Choice You’re Actually Making
Strip away all the technical detail and the argument comes down to something simple.
When a legislature decides to adopt or reject ranked-choice voting, approval voting, or any other expressive ballot format, they are making two separate policy choices whether they realize it or not. The first is: should voters be allowed to express more than one preference? The second is: which mathematical procedure should we use to convert those expressions into a winner?
The first question is fundamentally about representation. Do we believe that a voter’s second and third choices carry legitimate democratic information? Do we think an election should tell us something about the electorate’s preference landscape, or just about who got the most marks? Is saving money on additional runoff elections worth the additional voting complexity? These are values questions, and reasonable people can disagree.
The second question is fundamentally about accuracy. Given that voters have expressed their preferences, which counting method best reflects the actual distribution of those preferences across the electorate? This is not primarily a values question — it is closer to an engineering question. It has better and worse answers, and the answers change as our tools improve.
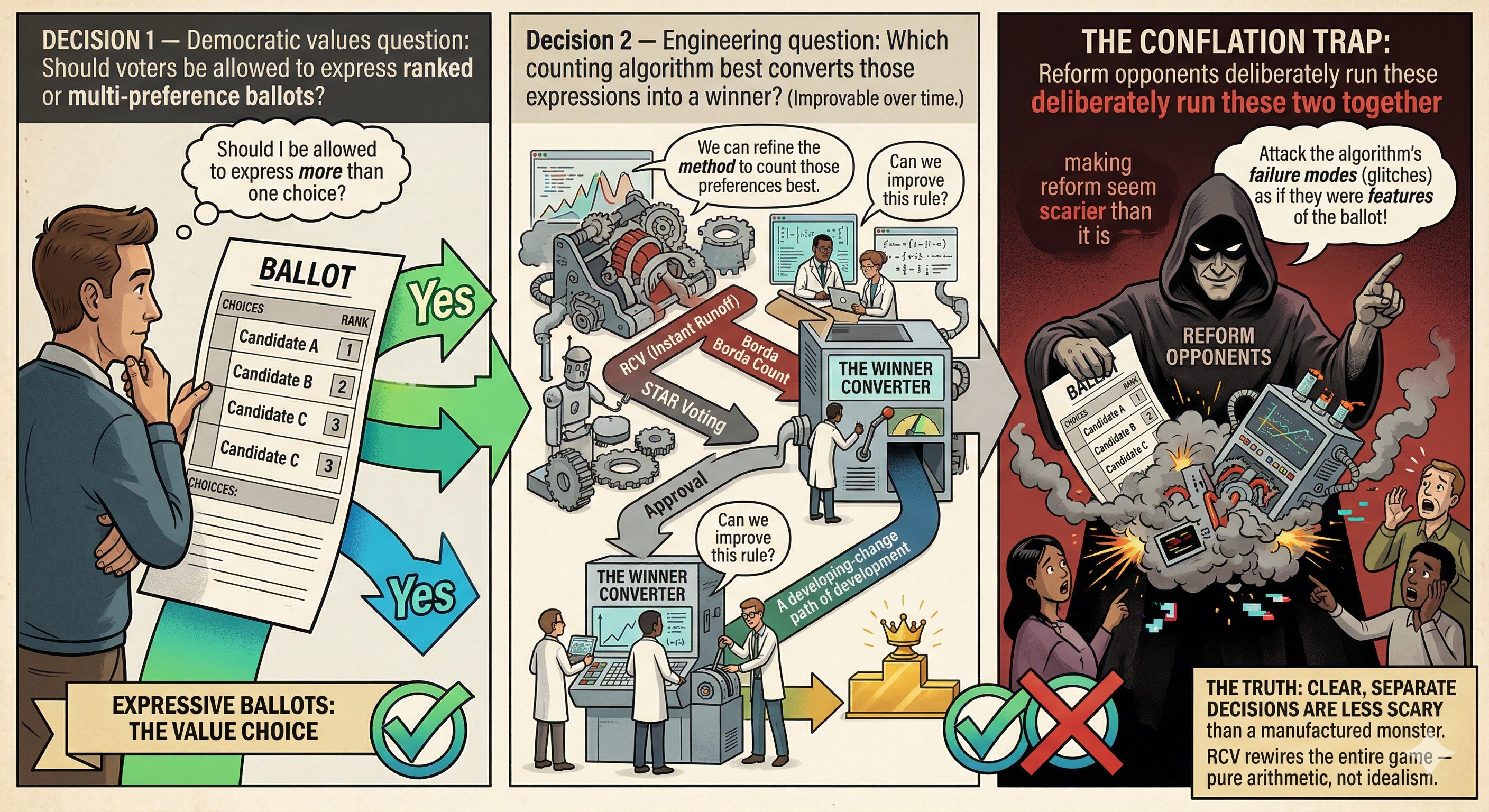
The Two Decisions, Separated
Decision 1: Should voters be allowed to express ranked, scored, or other multi-preference ballots?
This is a political and democratic values question. Arguments: representation, voter autonomy, the right to say “I accept B if I can’t have A” versus concerns about complexity, cost, tradition, and whether richer expressions change who participates.
Decision 2: Which counting algorithm should convert those preferences into a winner?
This is an engineering and accuracy question. Arguments about center-squeeze, manipulation resistance, majority winners, speed of results — all of these are arguments about specific counting families, not about expressive voting itself. The optimal counting algorithm is a moving target that improves as mathematical and computational tools improve.
Most current political debates about “RCV” conflate these two decisions into one. Separating them makes the debate more honest, makes objections more specific, and makes the path to improvement much clearer.
The conflation has a beneficiary. Opponents of electoral reform — primarily the two major parties, their operatives, and the financial interests, who have every institutional incentive to preserve the two-party lock that FPTP creates — have found it strategically valuable to direct every objection at the ballot format rather than the counting algorithm. If you can make voters afraid that “ranked-choice voting” will cause chaos, lose their ballot, or produce wrong answers, you don’t have to argue that every voter should be forced to choose between two options even when both are unacceptable.
This has been effective. In 2024, all four statewide RCV ballot measures outside Alaska failed — and post-election surveys showed that many voters cited confusion about what they were voting on, not principled opposition to expressing ranked preferences. The frame that reform opponents used — treating the ballot format and the counting algorithm as a single thing called “ranked-choice voting” and attacking the counting algorithm’s failure modes as if they were features of the ballot — worked.
The honest response is to separate the questions clearly. You can support expressive ballots and still have legitimate concerns about the instant-runoff counting algorithm. You can support the principle that voters should be able to say more than one name and still want a different method for counting what they said. That is a tractable political position that finds common ground across a wide range of voters. And it points directly at what can actually be fixed: not the act of asking voters for more information, but the mathematical procedure we use to interpret it.
7. What Good Counting Reform Looks Like
A few concrete markers for what a better counting conversation would produce:
Counting algorithm neutrality. Ballot access legislation should specify the ballot format (ranked, scored, approval, mixed) and mandate that the counting algorithm be transparent and auditable, without locking in a specific algorithm that cannot be updated. This is how software standards work: you specify what the interface must do, not which code must implement it. The counting algorithm should be improvable by administrative action; the ballot format, once adopted, should be stable.
Separating the legal standards. Most state constitutional language about “majority winners” and “plurality” was written before expressive voting was even imagined. Courts and legislatures should interpret these provisions in light of the actual democratic purpose they were meant to serve — ensuring the winner has genuine popular support — rather than as requirements that any specific counting procedure be used.
The Georgia case as a template. Georgia already uses instant runoff for military and overseas voters in its runoff elections — six states do. The state runs expensive, lower-turnout separate runoff elections for everyone else, at a cost of $75 million in public funds just for the 2020 Senate races. The argument that IRV is too complicated to use is contradicted by the fact that the state is already using it for some voters. The conversation in Georgia is not about whether expressive counting is possible — it is about whether the algorithm being used is the best available one, and whether it should be extended to all voters.
Openness to improvement. The field of social choice theory — the mathematical study of how to aggregate preferences — is active and advancing. Researchers working at the intersection of economics, computer science, and political science are developing counting methods that could extract substantially more information from the same ballots voters are already casting. These methods are not ready for deployment today. But they will be. Writing counting algorithms into law rather than into administrative code makes it harder to adopt improvements when they arrive.
The Counting Room Matters
The previous articles in this series have made the case that expressive voting — letting voters say more than one name — produces better candidates, more civil campaigns, better-informed electorates, and election outcomes that more faithfully represent what voters actually want. That case stands.
This article adds a structural argument to that case: the specific objections that have been most effective at blocking expressive voting reform are largely objections to particular counting algorithms, not to the underlying idea. The center-squeeze problem is a real limitation of instant runoff counting. It is not an argument against letting voters rank candidates. Separating these two things doesn’t weaken the case for reform — it strengthens it, by making the target more precise.
The counting room is not a neutral technical space. The choices made there determine whose preferences get registered and whose get discarded. In an era when the mathematical tools to make those choices more faithfully are advancing rapidly, the argument for locking in nineteenth-century counting procedures grows weaker every year.
The game should be worth playing for its own sake. The counting room should be the part that ensures it was played fairly, that is engineered to ensure the game is played securely and fairly.
Part of the Expressive Voting series. Previous articles: What Your Vote Actually Does · One Ballot, Many Languages · Why Nice Campaigns Win · Does Anyone Actually Know What Your Candidates Believe? · Why the People in Charge Don’t Want You to Vote Better